
What's In-Context Learning in Deep Learning and Why It's so Cool?
LLMs can learn from a few example and even "learn" tasks that contradict their pre-training distribution. Wild stuff ahead.

In this edition, I wanted to explore a very weird topic in deep learning more specifically relating to large language model.
In-Context Learning.
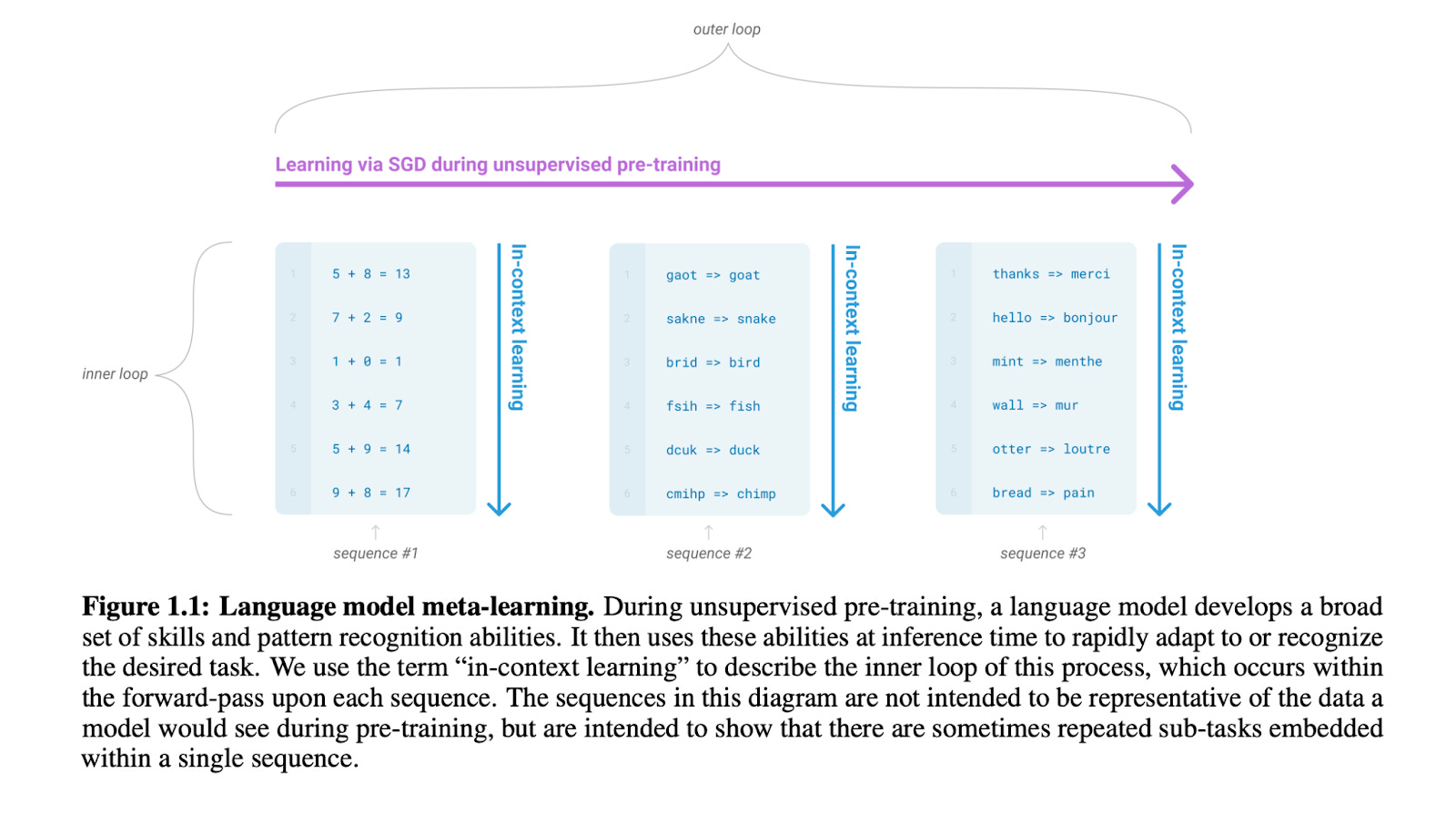
If you never heard the term this issue is for you.
Basically if you are using LLM like Gemma or GPT-4 chances are you already have used in-context learning.
Something like the following prompt would qualify as asking a model to do in-context learning:
Circulation revenue has increased by 5% in Finland. \n Neutral
Panostaja did not disclose the purchase price. \n Negative
Paying off the national debt will be extremely painful. \n PositiveThe company anticipated its operating profit to improve. \n __________ ← to complete
In that particular case, the output for something like GPT-4 looks like this:
The sentiment for "The company anticipated its operating profit to improve" is Positive.
How the heck did the model understood that:
This was a sentiment analysis task?
That it needs to respond Positive or Negative?
We’ll explore that in this issue!
btw: for the visual folks out there, there is a video + deck version available on my Youtube channel.👇
Definition
In a nutshell, In-Context learning is loosely defined as showing a few examples of input and output to a large language model and just by conditioning on the prompt the model can learn how to do a new task.
In-context learning like many things in machine learning is a bit of a confusing terminology. There isn’t any learning happening in the traditional machine-learning sense (i.e. the weights of the models aren’t changing).
However, something is happening within the models that feel like it understands the tasks that are requested.
The term in-context learning originated from GPT-3 in the paper that introduced the model title “Language Models are Few-Shot Learners”.
Few-Shot in this context is giving a model a few examples to train on a new task
Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches.
[…]
For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
The sentence above is absolutely bonkers from a machine-learning standpoint.
The gist of it is that by showing one or a few examples of the input-output pairing of what the task is, the model can drastically improve its performance as seen below.

The interesting point on the graph is:
This ability emerge at a rate proportional to the size of the models (175B curve is steeper than 13B). Yet even in the 13B, there is in-context happening, except at a rate that requires more examples to be given in context.
There is a very sharp improvement in the larger 175B model when 1 example is given and the performance keep increasing as more natural language examples are showcased to the model.
To leverage in-context learning in practice the last output pairing needs to be left blank so that the LLM can fill it out as in the example above.
There are many ways to use in-context learning as it is versatile in a wide variety of tasks and can even be used to make external calls to APIs in the case of toolformers architecture.
Why is it Surprising?
Being able to learn on the fly with a few examples isn’t something new, meta-learning that allows for optimizing a model for few-shot learning already existed well before GPT-3.
The reason why in-context is leaving researchers quite puzzled is that it wasn’t part of the training procedure at all.
Remember, in-context learning originally emerged in big transformer models trained on next token prediction from internet scale data.
There is nothing in this training regiment that explicitly conditioned the models to develop that capability.
Yet, it happens consistently and allows for LLMs to be a massively versatile interface if conditioned properly with input and output (like in this GPT-4 example prompt):

There are two connected leading hypotheses of how this emerging ability is working, let’s explore them.
Hypothesis 1: Bayesian Inference Framework
The first prominent hypothesis for how in-context learning could work comes from Xie/Min et al, where the authors proposed a Bayesian framework explaining this emergence.
In a nutshell, the LLM uses the in-context learning prompt with input/output examples as a guide to locate the previously learned latent concept within its weights.
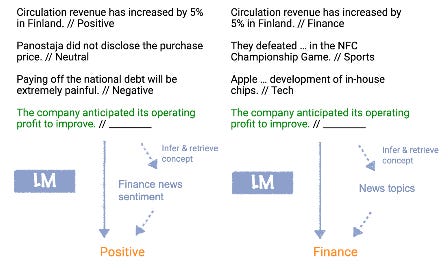
As you can see in the picture above, the LLM could be infering and retrieve the right concepts depending on the content of the prompt.
In this framework, the LLM is learning and inferring the concept of two things:
the pre-training concepts distribution while it was trained to do the next token prediction.
the prompt examples concepts distribution which usually share a common theme.
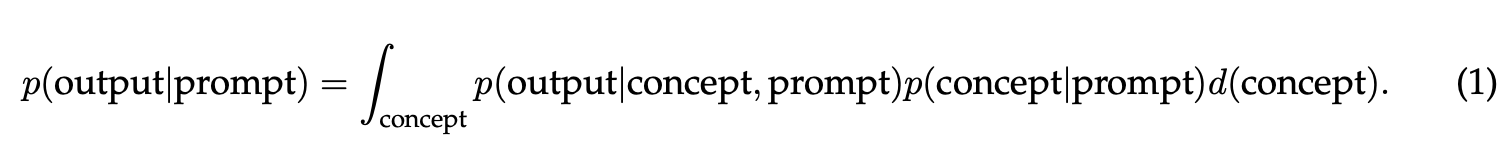
In this framework, the prompt examples are used to “sharpen the posterior distribution over concepts”. As we add more examples in the prompt we are helping the model select the right concept to sample within the “p(concept | prompt)” part of the formula.
Here the prompt information can be separated into two:
Signal: which are the training examples and the information contained within.
Noise: which are the transition between examples or even the correctness of the input-output pairing.
The basis here is that if the signal-to-noise ratio is high in-context learning can emerge. Interestingly, some noise can be added to an in-context learning setting that would make no sense for a supervised learning algorithm but would leave an LLM unbothered (e.g. like having all the output labels being randomized).

As we see here, by having enough signals the model learned:
the input and output pairing structure for the task.
the type of task: sentiment analysis.
Even though there is a tremendous amount of noise in the output (i.e. all the bottom examples are random!) it kind of doesn’t matter much for the model in such a task setting.
If we were to break down the content of an in-context learning prompt, it would look like this:
Input distribution (very important)
Input-Output mapping (not so important)
The format used (important)
Output space (very important)

This idea was explored concurrently from another angle by the smart folks at Anthropic as they found a circuit they call an induction head in transformer architectures.
This type of sequence gets its name from inductive reasoning because:
In inductive reasoning, we might infer that if
Ais followed byBearlier in the context,Ais more likely to be followed byBagain later in the same context.
Even in the toy transformer network they studied, the researchers at Anthropic quickly realized that the presence of such a circuit in the network meant the architecture was implementing an algorithm within.
Notice that induction heads are implementing a simple algorithm, and are not memorizing a fixed table of n-gram statistics. The rule [A][B] … [A] → [B] applies regardless of what A and B are.
Which bridges the gap to the second hypothesis.
Hypothesis 2: LLMs are Implementing Learning Algorithm Implicitly
Now the second hypothesis of how in-context emerge is that the transformer-based in-context learners are literally implementing learning algorithm implicitly somewhere within their weights structure.
It has been shown that transformers architecture even of small size can implement gradient descent in the paper “Transformers learn in-context by gradient descent”.
One of the most compelling arguments that the big LLMs are implementing a learning algorithm to help with in-context learning tasks comes from a paper by the Google Research team titled “Larger Language Model do In-Context Learning Differently“
It was shown by the team at Google Research that if models are large enough they gain the ability to override their prior pre-training distribution and learn a new erroneous input-output mapping.

What we see in the figure is that we are feeding increasingly more flipped label percentages for an in-context learning task to various models. As we increase the number of wrong examples what we witness is that the bigger models like PALM-540B are overriding their typical internal in-context behavior of not listening to input-output mapping.
Note that it still requires enough flipped labels for this “failure” at the task to appear in these large models since the hypothesis is that the models are quite literally using function mapping from input to output during an in-context task.

Something similar is happening with what is called “Semantically-unrelated targets in-context learning” which is a fancy way of saying “replace the output with random words like Apple or Oranges.
Small models struggle throughout, while larger models get better and learn the right mapping for the task.
Where Are We Now?
So, for both hypotheses highlighted in this newsletter, the mechanism seems to be a contextual activation of the right embeddings or knowledge domains within the model and this activation seems to be producing the right output.

The current research direction is pushing the boundaries towards that second hypothesis quite heavily with articles such as:
Transformers Learn In-Context by Gradient Descent
Trained Transformers Learn Linear Models In-Context
Pretraining task diversity and the emergence of non-Bayesian in-context learning for regression
What In-Context Learning “Learns” In-Context: Disentangling Task Recognition and Task Learning
If this research direction of big language models yields positive results, there is a very good case to be made to just “train larger models and see what emerges”.What other meta-learning ability will appear as the number of parameters increases?
Conclusion
Anyway, this is a fascinating topic and I believe that a solid understanding of the mechanism of in-context learning will help us develop the next generation of AI models.
If you want to dig even deeper than this first introduction, check out these awesome resources:
Also, for a more detail-oriented explanation of in-context learning check out Sang Michael Xie's contribution.
If you have questions or additional thoughts, let’s continue this conversation in the comment section!
Hope it was useful! 🌹
Best,
Yacine Mahdid