
The TLDR on DeepSeek R1
Simpler than I originally thought!

Hello everyone,
Hope you are doing fantastic today!
I’ve been reading DeepSeek R1 last week.
I found the method, results, and just the general ideas within that paper super interesting.
I’ve made a walk-through over here if you are interested in going through it step by step:
Here is the TLDR and a map to follow along:

The end output of the R1 research is three family of reasoning models (all open source):
DeepSeek R1-Zero
DeepSeek R1
DeepSeek R1 distilled into Llama and Qwen
All model creation pipelines have a root based on DeepSeek V3, a huge 600+B parameter model (also open source).
The research is doing post-training to induce reasoning into DeepSeek V3. Aka, try to make the model talk to itself in order to be better at complex tasks like coding, engineering, and problem-solving.

As seen above, DeepSeek R1 performance is on par with Open AI o1 which is closed source. Arguably replicating their methodology.
The interesting first result is that DeepSeek R1-Zero pipeline involves Reinforcement Learning with no human in the loop.
To prompt the model, they used this very simple prompt:

By adding a proper reward function on top of that prompt, the model was able learn to think longer and induce reasoning over time.

This increase in reasoning in the model is correlated directly with an increase in performance over time for DeepSeek-R1-Zero.
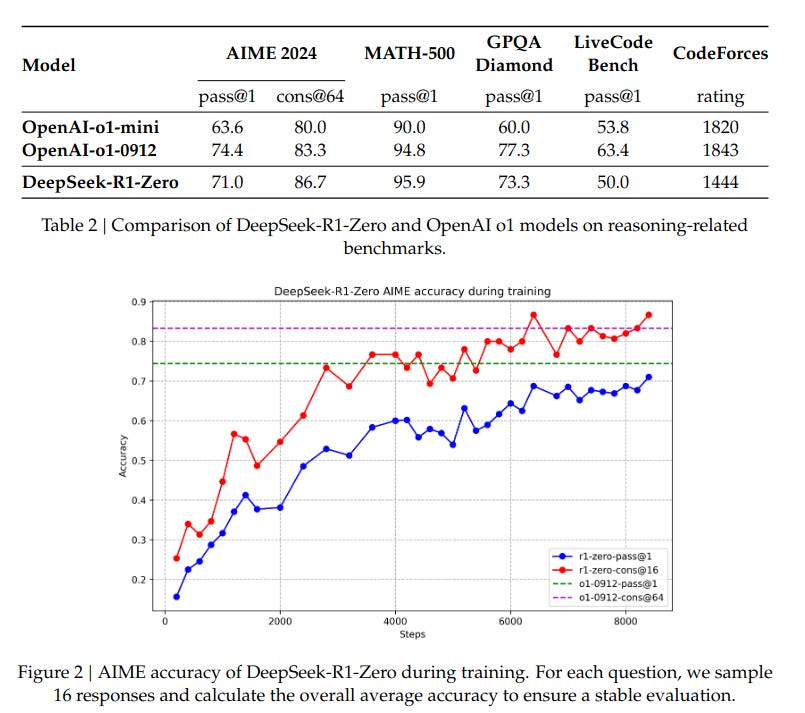
The magic of DeepSeek R1-Zero not requiring human feedback during the reinforcement learning process hinges on the Groupe Relative Policy Optimization (GRPO) and their rewards function.
For GRPO we have the following:

Which basically says:
use current log probabilities for the policy across the group (pi) scaled by the old policy times the normalized reward (A) as an optimization step.
don’t take too big a step compared to the old policy though (clip part).
don’t diverge too much from DeepSeek V3 to parameters (KL divergence part).
For the reward:
The reward function at this point in the research was all deterministic and made sure the formatting of the reasoning stayed within the think tag:

This is a big deal as it breaks with the idea that we require reinforcement learning from human feedback (RLHF) to induce reasoning in models.
However, DeepSeek R1-Zero reasoning was difficult to decode, so the researcher posited that finetuning DeepSeek V3 prior to doing reinforcement learning would help the performance.
To do so, they made a whole complicated pipeline that consisted of generating reasoning and non-reasoning data in a multistep training process (see map - I got in painstaking detail in the video).
In the end they get a solid model, on par with o1, and with an intelligible reasoning context:

To make the models broadly useable they used distillation using R1 into smaller models like Qwen and Llama. The results are also very performant and MUCH smaller:

Finally, when they tried to run their reinforcement learning pipeline on a smaller model vs using distillation, they realized that distillation was better:

The bottom line for the distillation part is that it seems like reinforcement learning “heightens” the reasoning core that is already present in the very big models vs not really sharp in the smaller ones natively.
You can find all these models on Ollama and you can play with them easily on your GPUs:
That’s it!
Hope you enjoyed the TLDR, for more detailed information I suggest you check out the tutorial or the paper directly:
📌 https://arxiv.org/pdf/2501.12948
Have a great week everyone! 👋