
Going too deep in R1...
Why Deepseek R1 KL divergence looks like that?

I’ve been studying in-depth deepseek’s R1 this past month and I like the paper.
Something about it is just joyful from a research perspective, especially the level of transparency displayed.
One element that caught my eye is their implementation of KL divergence as a penalty term in their GRPO formula:

For those who don’t know, KL Divergence is simply a statistic that measures the difference between two probability distributions. It’s tightly related to cross-entropy and entropy.
It’s used in R1 to “anchor” the model that is learning to reason with a “reference” model (Deepseek V3 in that case).
This means that if the policy model starts to behave very differently than the reference model it needs to have a strong performance to justify it.
This term is used differently in PPO vs GRPO:

The first thing to notice is that they shifted KL away from the reward term compared to PPO and directly into the policy model training.
In PPO the formula where KL divergence is being applied looks like this:

In the GRPO the KL portion looks like this:

Widely different implementation!
You might just nod and say “Fair enough, that’s KL divergence”. But it looks nothing like it… How did they come up with that penalty term?

If you go down the rabbit hole, like I did, you find an interesting truth that is at the root of the deep learning mindset. More on that at the end.
You can check out my video of the subject if you want a walkthrough:
The TLDR is that it’s empirically a very good Monte-Carlo approximation of KL divergence, with less variance than the version from the PPO algorithm while still being unbiased.
The proof of that isn’t even another research paper, it’s just a blog post that one of the co-founders of OpenAI, Schulman, posted in 2020:

Yet, the flow is elegant and I suggest you take a look at it (slowly): http://joschu.net/blog/kl-approx.html
In a nutshell here is the flow:
We can’t use KL divergence directly as it’s impractical for RL purposes and we don’t need to be too correct. The approximation is good enough for the training procedure.
The first approximation k1 is
log(q/p)which is what PPO is using. This is an unbiased approximation but has high variance since k1 can be negative while the true KL cannot (bounded by [0,inf[)The second approximation Schulman proposes k2 is
0.5*log(p/q)^2which is a biased estimator, but with lower variance than k1. It has lower variance because it’s an f-divergence like KL and one of the properties of f-divergences is that when the probability distribution p and q are very similar, all f-divergences look roughly like KL.The third approximation k3 is
(p/q -1) - log(p/q)which is what we find in GRPO (a bit rearranged). This is an unbiased estimator because it is k1 + a control variate (p/q -1). That control variate has 0 expectation so it doesn’t change the biasesness of k1.
When Schulman ran the simulation he got the following results:
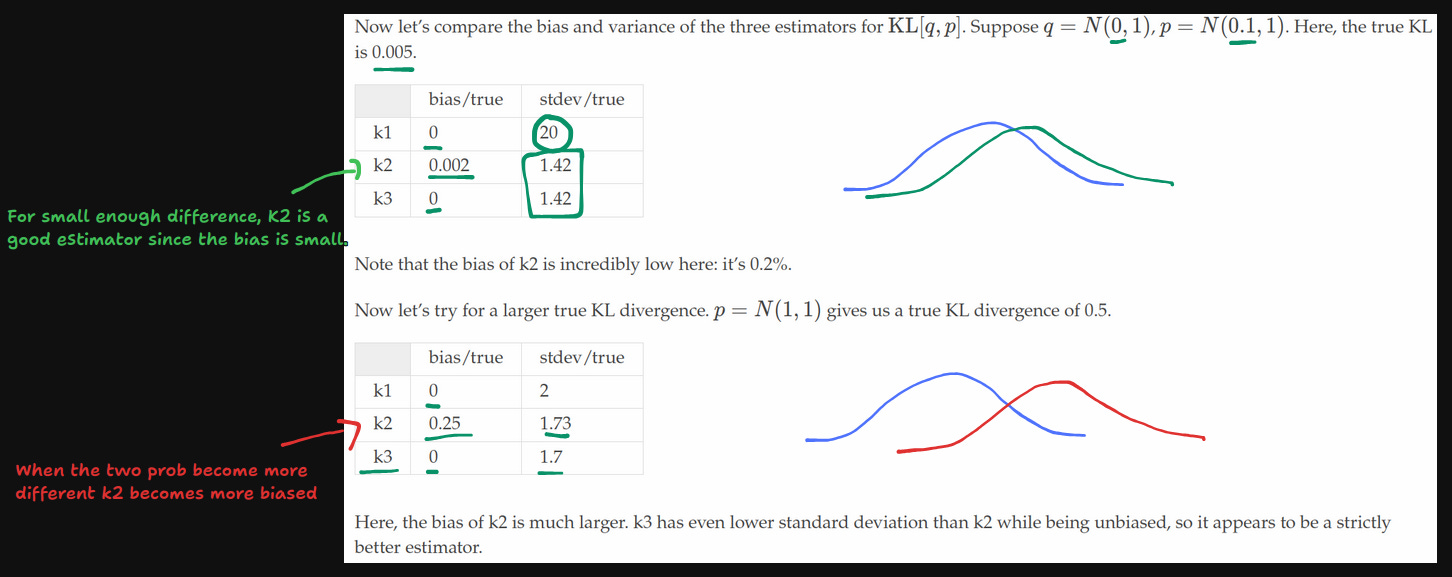
This shows that k3 seems to be strictly better, while k2 is not performing too badly either except when the true KL is getting larger.
What’s the takeaway?
A good portion of deep learning is very empirical. Is PPO wrong for using k1 instead of k3? Maybe, maybe not.
It might not even impact the training that much and that high variance penalty term might be just good enough.
Should k2 be used in GRPO or PPO? Maybe, maybe not.
It’s all about tradeoffs and validating empirically what yields at the end of the day the best model.
When you dig deep enough into the internals of deep learning systems, you realize the thousands of tiny design decision that have been made to get to the result.
Beautiful to gaze upon as a researcher.