Large Language Models Learn to Use Tools at 775M Parameters
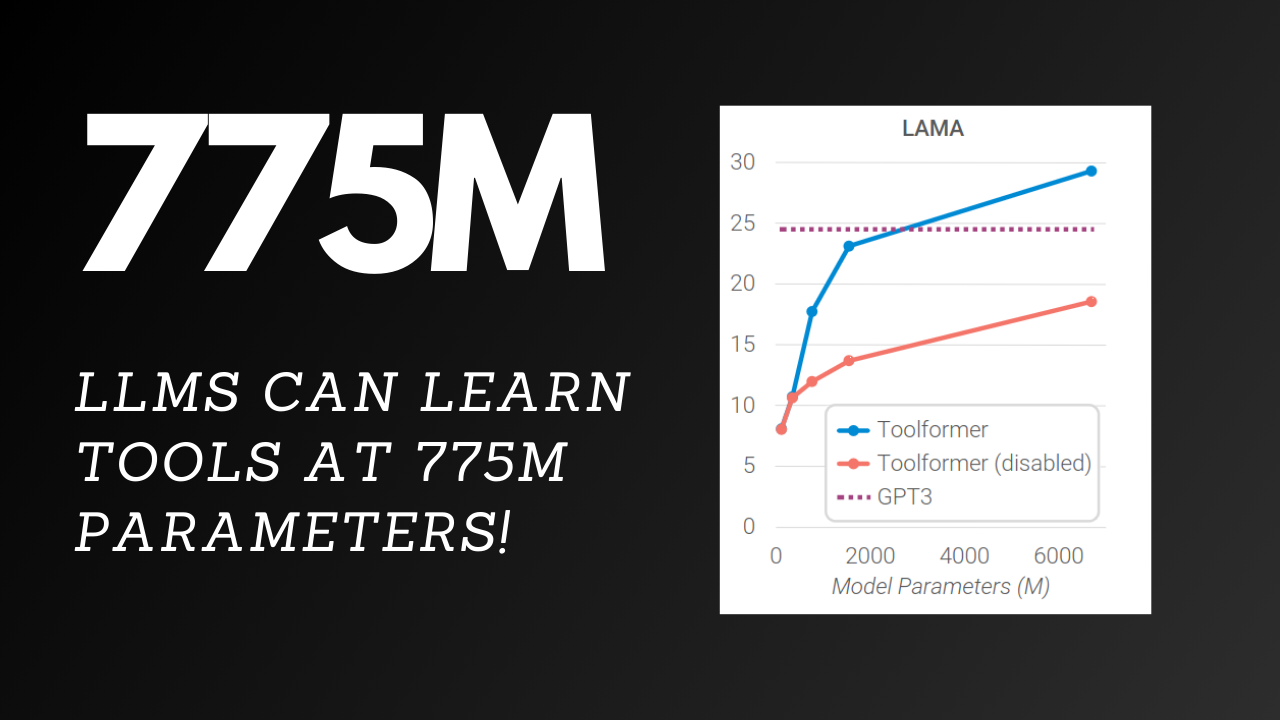
The ability for LLMs to learn how to use tools seems to emerge at around 775M parameters. In a study where they gave this learning capacity to LLMs of various size , the authors found that LLMs could only use them effectively when they had a size of 775M and above.
A very interesting result emerged from the paper “Toolformer: Language Models Can Teach Themselves to Use Tools” by the Meta AI Research Lab in early 2023.

This specific result caught my attention for its seemingly neuroscientific explanation (which might not be even relevant).
I like brains and I couldn't help but be fascinated by the potential implications.
The result is that LLMs' ability to learn how to learn to use tools emerges at around 775M parameters and not before.
The distinction is important here.
The training regiment used in this research makes it so that the LLMs were teaching themselves how to use new tools through API calls.

Toolformer is what the authors call this learned capacity that can be tacked on top of any model, but only the models with more than 775M parameters can use it effectively.

We’ll dive into the methodology in a few, but first, let’s look at the result!
Result: LLMs Learn Tools 🐒
There are a bunch of interesting results throughout this paper, however, the one I'm highlighting happens in Figure 4!
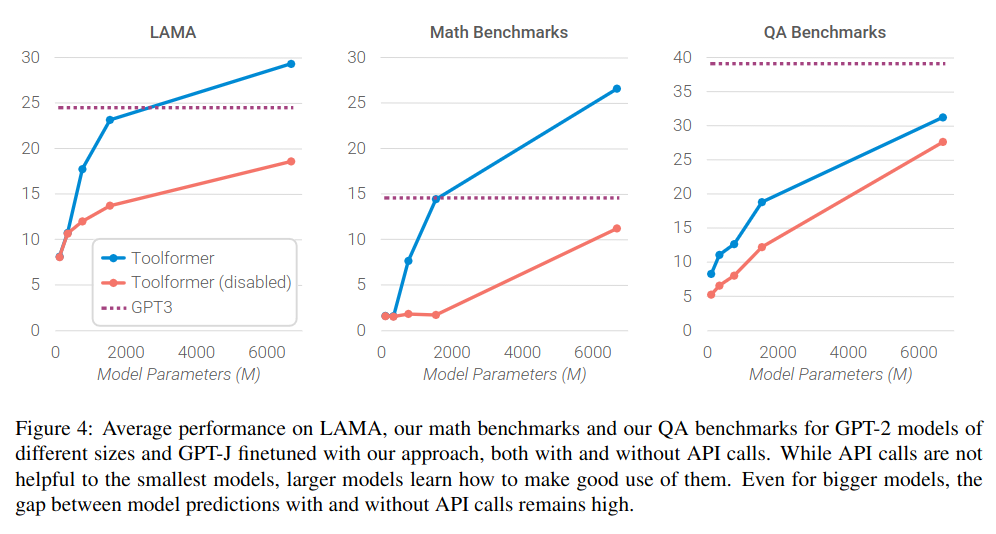
There are three main subgraphs of interest for this specific result. Each of the subgraphs has the same composition:
Five different models are examined and compared against GPT-3 (175B parameters).
On the Y axis, you have the performance for a given benchmark.
On the X-axis, you have the size of the model in millions of parameters.
For the lines we have:
- The dotted line is GPT-3 results.
- The orange line is each model baseline with no ability to learn how to use tools.
- The blue line is each model with the ability to learn how to use tools.
On the blue and red lines, the dots represent the actual models.
Let’s take a look at each subgraph one by one
LAMA Benchmarks
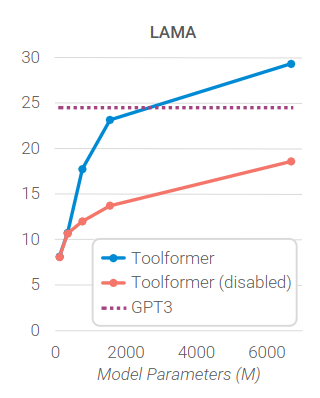
LAMA benchmark is a set of tasks where the model needs to complete a statement whether a date or fact. It was devised to probe the knowledge of a language model.
{"masked_sentences": ["To emphasize the 50th anniversary of the Super Bowl the [MASK] color was used."], "obj_label": "gold", "id": "56be4db0acb8001400a502f0_0", "sub_label": "Squad"}
{"masked_sentences": ["Von Miller plays in [MASK] position for the Denver Broncos."], "obj_label": "linebacker", "id": "56bf17653aeaaa14008c9513_0", "sub_label": "Squad"}
{"masked_sentences": ["The TGIF comedy Family Matters for the 1997-98 season was originally aired by [MASK]."], "obj_label": "CBS", "id": "57273b69dd62a815002e99d8_0", "sub_label": "Squad"}As we can see in Figure 4, the two smallest models have the same performance in LAMA whether they have their toolformer ability disabled or not (blue and orange dots are at the same performance).
Meaning that their new ability is useless to improve performance.
At 775M parameters, the performance of the model with toolformer ability is vastly superior to the baseline.
This trend keeps up with bigger models, culminating with the 1.6B model outperforming the 175B model GPT-3 (by like a lot)!
Math Benchmarks
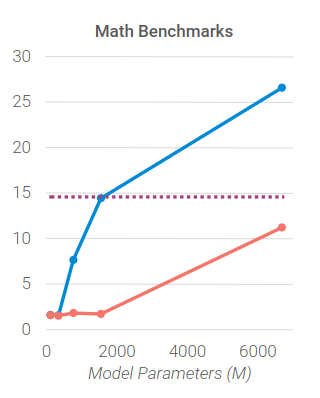
A similar story is sketched out during the math benchmark with an even greater gain in relative performance for models past 775M parameters.
This result is interesting because LLMs are notoriously poor at math, especially models with small capacity. This makes sense as they are trained on words not explicitly to understand all the intricacy of numbers and operators.
However, by allowing them to use tools, like a calculator, they are able to more easily overcome this inherent limitation (as long as they are above 775M parameters).

QA Benchmarks
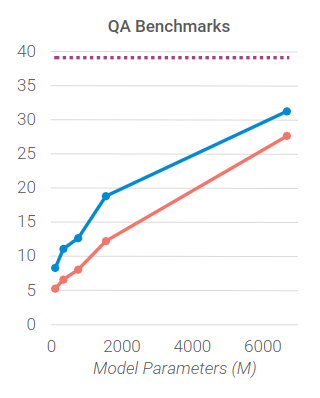
This result is different than the others and adds a nuance that paints a great picture.
As you can see, all models are improving with their newfound toolformer ability. This wasn’t the case with the previous two benchmarks!
What does it mean then if during the QA benchmarks all models are improving?
Let's look at the main tool used during the QA type of task by toolformer models:

As we can see above in blue, the interface for the tool is very simple. It's literally asking "What/Who/Why" followed by the term the model needs to complete.
This makes it a very easy tool to use compared to the other interface which requires a bit more general understanding.
Therefore, as the authors point out, there seems to be a tight connection between the complexity of the tool required to complete a given task and the capacity of the models.
Since the models aren't explicitly taught when to use what tool, the model needs to have just enough internal capacity to figure out which tool to use and how to use it.
In the case of QA tasks, the tool happens to be simple enough for that chain of events to flow correctly for a model smaller than 775M parameters!
As for the other types of tasks, it's too complicated for the smaller models to do the toolforming movement properly.
Neuroscience Tangent 🧠
The cool thing about this result is that it seems to mirror the fact that brains with low capacity don't really use tools and those with higher capacity do.
It also is similar in the sense that brains with high capacity, like human brains, can figure out when and where to use the tools they have been shown a few times. They don't have to be explicitly trained for all types of tasks.
All in all, it's a pretty cool result. Let’s check out the methodology.
Methodology: API + In-Context Learning 🎓
Without going into the full paper let’s elucidate how the author arrived at this result.
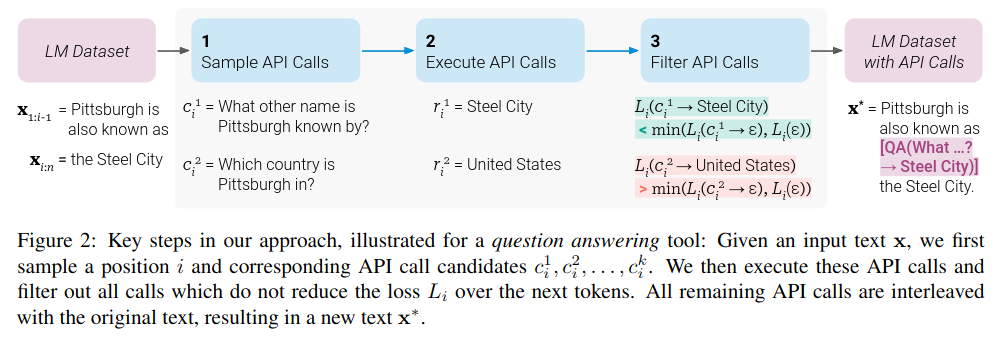
Firstly, as pointed out earlier, the author where trying to teach the models how to themselves learn how to use tools.
By tools, we mean those wrapped in APIs :
- Question and answering
- Calculator
- Wikipedia Search
- Translation System
- Calendar.
They weren’t teaching the model one type of tool for each possible situation, but a multitude of them without any target task.
The training regiment to learn the interface they could work with consisted of:
- A few examples of how to use the APIs.
- These examples were then augmented through the use of in-context learning.
- Then this augmented dataset was used for fine-tuning the model.
This is pretty cool because it means that there wasn't a massive data labeling effort going on! A few examples were enough for the model to effectively learn how to use the APIs!

After finetuning, the toolformer model had to figure out which tool they should be using for whatever task they had in front of them.
They did so by making the API call and inserting the result at the right spot in the output.
That’s the condensed version of the methodology! Do check the paper for all the details, it's well worth the read!
Conclusion
To conclude, the authors taught a model how to use tools and it had to decide when and which tool to use. The tooflormer model was able to leverage this newfound knowledge to perform various benchmark tasks.
The models with 775M+ parameters were the only ones to be able to gain an advantage as they understood how to use the tools effectively (except for very simple tools and tasks involving QAs).
If you have any questions don’t hesitate to email me at mail@yacinemahdid.com !
I'm on vacation right now, so I'm pretty much chilling and reading research papers all day at the beach.

Have a great week! 🌹